Optional使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
User user = User.builder()
.id(1L)
.name("zxalive.com")
.address(Address.builder()
.country("中国")
.city("上海")
.postalCode("000111")
.build())
.build();
Optional<User> userOptional = Optional.ofNullable(user);
Optional.empty(); // 获取一个Optional对象,value为null
Optional.of("not null"); // 参数不可空,否则NPE
Optional.ofNullable(user); // 如果value为null,返回value为null的Optional对象,否则生成一个value为传入value的对象
userOptional.get(); // 获取value值,如果value为null,则抛出异常NoSuchElementException
userOptional.isPresent(); // boolean
userOptional.ifPresent(System.out::println);
userOptional.filter(u -> u.getName().length() > 12); // 过滤,无则返回Optional.EMPTY
userOptional.map(User::getAddress); // 映射
userOptional.map(User::getAddress).map(Address::getPostalCode); // Optional<Optional<String>>
userOptional.map(User::getAddress).flatMap(Address::getPostalCode); // Optional<String>
userOptional.orElse(User.builder().build());
userOptional.orElseGet(() -> User.builder().build());
userOptional.map(User::getGender).orElse(1);
userOptional.map(User::getId).orElseThrow(() -> new Exception("取值错误"));
// NULL 对象也能map
User nullUser = null;
Optional.ofNullable(nullUser).map(User::getId).orElse(999L);
List<User> users = null;
List<String> list = Optional.ofNullable(users).orElse(Collections.emptyList()).stream().map(User::getName).collect(Collectors.toList());
userOptional.equals(userOptional); // 比较 value
userOptional.hashCode();
userOptional.toString();
Stream.of(nullUser).forEach(s -> {
});
|
Stream流基本使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
/**
* https://github.com/hellokaton/30-seconds-of-java8.git
* https://github.com/RichardWarburton/java-8-lambdas-exercises.git
*/
class Stream流 {
public static void main(String[] args) {
// 流的创建
String[] strings = new String[]{"a", "b", "c", "d", "e"};
Arrays.stream(strings);
// 基础api
filterStream.skip(1).limit(10);
filterStream.findFirst();// 返回第一个
filterStream.distinct();// 去重 需要重写User对象的equals方法和hashCode方法
filterStream.count();// 统计
// anyMatch、allMatch、noneMatch
Stream.of("A", "B", "C", "D").anyMatch(s -> s.contains("A")); // true 匹配任意1个
Stream.of("A", "B", "C", "D").allMatch(s -> s.contains("A")); // false 全部匹配
Stream.of("A", "B", "C", "D").noneMatch(s -> s.contains("E")); // true 无匹配
// flatMap 将多级流 进行映射后平铺 多个集合的流 -> 一个集合的流
Stream<List<Integer>> listStream = Stream.of(Arrays.asList(1, 2), Arrays.asList(3, 4));
listStream.collect(toList()); // [[1, 2], [3, 4]]
listStream.flatMap(Collection::stream).collect(toList()); // [1, 2, 3, 4]
users.stream().flatMap(user -> Stream.of(user.getName(), user.getScore())).collect(toList()); // [张一, 100.0, 张二, 100.0]
// flatMap和map对比
users.stream().map(user -> user.getPhoneList().stream()); // Stream<Stream<Phone>>
users.stream().flatMap(user -> user.getPhoneList().stream()); // Stream<Phone>
// 统计
filterStream.map(User::getName)
.filter(Objects::nonNull)
.filter(name -> Character.isDigit(name.charAt(0))); // 字符串首字母为数字
// 统计 字符串 小写字母的个数
long count = Optional.of("stringTTTT").orElse("")
.chars()
.filter(Character::isLowerCase).count();
}
}
|
Stream流 groupingBy集合分组、多字段分组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
class 分组 {
public static void main(String[] args) {
final Stream<User> filterStream = Optional.ofNullable(users).orElse(Collections.emptyList())
.stream()
.filter(Objects::nonNull)
.filter(s -> s.getGender() != null)
.filter(s -> s.getAge() != null)
.filter(s -> s.getScore() != null);
// 1参数
filterStream.collect(groupingBy(User::getGender)); // Map<Integer, List<User>>
// 2参数
filterStream.collect(groupingBy(User::getGender, counting())); // 统计:counting
filterStream.collect(groupingBy(User::getGender, summingInt(User::getAge))); // 聚合:summingInt/summingDouble/summingLong/averagingDouble
filterStream.collect(groupingBy(User::getGender, mapping(User::getAge, toList()))); // 映射:mapping
filterStream.collect(groupingBy(User::getGender, mapping(User::getAge, toCollection(TreeSet::new)))); // 自定义收集器
filterStream.collect(groupingBy(User::getGender, mySorted(comparing(User::getAge)))); // 自定义收集器,toSorted方法返回 Map<Integer, User>
filterStream.collect(groupingBy(User::getGender, collectingAndThen(maxBy(comparing(User::getScore)), Optional::get))); // toSorted方法原理
filterStream.collect(toMap(User::getGender, Function.identity(), BinaryOperator.maxBy(comparing(User::getScore)))); // 上面操作实际就是tomap
// 多级分组 + 后续操作
filterStream.collect(groupingBy(User::getId, groupingBy(User::getAge, groupingBy(User::getGender)))) // Map<Long, Map<Integer, Map<Integer, List<User>>>>
.forEach((id, ageUserMap) -> {
ageUserMap.forEach((age, genderUserMap) -> {
genderUserMap.forEach((gender, userList) -> {
});
});
});
// 多字段分组
List<User> users = filterStream
.collect(groupingBy(s -> Pair.of(s.getGender(), s.getDepartmentName()), counting()))
.entrySet().stream().map(entry -> {
entry.getKey().getLeft();
entry.getKey().getRight();
entry.getValue();
return User.builder().build();
}).collect(toList());
filterStream
.collect(groupingBy(s -> Pair.of(s.getGender(), s.getDepartmentName()), mapping(User::getName, toList())))
.forEach((key, value) -> {
key.getLeft();
key.getRight();
List<String> names = value;
});
// 3参数
filterStream.collect(groupingBy(User::getGender, TreeMap::new, toList()));// TreeMap<Integer, List<User>> 上游指定收集器TreeMap 下游收集器List
// groupingBy 保留null分组
stream.collect(groupingBy(s -> s.getGender() == null ? "null" : s.getGender()));
stream.collect(groupingBy(a -> a.getGender() == null ? "mix" : a.getGender()));
filterStream.collect(groupingBy(s -> s.getGender() == null ? "null" : (s.getGender() == 1 ? "M" : "F")));
filterStream.collect(groupingBy(s -> s.getScore() == null ? "B" : s.getScore().compareTo(60D) >= 0 ? "A" : "B"));
}
/**
* 自定义收集器
* <p> collectingAndThen 收集后Function行为 </p>
*/
public static <T> Collector<T, ?, T> mySorted(Comparator<? super T> c) {
return collectingAndThen(minBy(c), Optional::get);
}
}
|
Stream流 summaryStatistics汇总统计
1
2
3
|
filterStream.mapToDouble(User::getScore).average(); // 聚合:average、sum
DoubleSummaryStatistics summaryStatistics = filterStream.mapToDouble(User::getScore).summaryStatistics();
summaryStatistics.getMax(); // getMin/getAverage/getSum
|
Stream流 peek可以消费的中间操作
1
2
3
4
5
6
7
8
|
// peek 可以消费的中间操作
List<String> arrayList = new ArrayList<>();
List<User> users1 = Optional.ofNullable(users).orElse(Collections.emptyList())
.stream()
.peek(user -> arrayList.add(user.getName())) // 存储数据
.peek(user -> user.setName(user.getName() + "666666")) // 统一修饰数据
.peek(user -> log.info("id:{}", user.getId().toString())) // 打印日志
.collect(Collectors.toList());
|
Stream流 collect定制收集、基础收集器
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 收集器 原始收集方式 stream.collect
filterStream.collect(toCollection(TreeSet::new)); // 定制集合收集
filterStream.collect(maxBy(comparing(User::getCount))); // 求极值 maxBy/minBy 可用专用收集器max
filterStream.collect(mapping(User::getName, toList())); // 映射 mapping 可用专用收集器map
filterStream.collect(partitioningBy(user -> 1 == user.getGender())); // 数据分块 partitioningBy
filterStream.collect(averagingDouble(User::getScore)); // 聚合:averagingDouble/averagingInt/averagingLong summingDouble/summingInt/summingLong
Stream.of("A", "B", "C").collect(toList());
Stream.of("A", "B", "C").toList(); // 上条简化
Stream.of("A", "B", "C").collect(joining(",")); // A,B
Stream.of("A", "B", "C").collect(joining(", ", "[", "]")); // [A,B]
String.join(", ", Arrays.asList("1", "2")); // 1, 2
filterStream.max(comparing(User::getCount));
filterStream.map(User::getName).map(String::toUpperCase);
|
Stream流 flatMap、concat流的平放、合并
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
class 平放_合并 {
public static void main(String[] args) {
List<List<User>> userss = new ArrayList<>();
userss.add(users);
// concat of
Stream<User> integerStream = userss.stream().flatMap(Collection::stream);
Stream<User> userStream = filterStream.flatMap(user -> Stream.concat(Stream.of(user), user.getUserStream()));
// 对比concat Stream.of 没办法统一对象类型
Stream<Object> objectStream = filterStream.flatMap(user -> Stream.of(user, user.getUserStream()));
Stream.of("11", "2");
Stream.of(Arrays.asList(1, 2), Arrays.asList(3, 4));
}
// concat使用场景
public static class concat {
interface PerformanceFixed {
String getName();
Stream<Artist> getMusicians();
// 返回乐队名 + 乐队成员
default Stream<Artist> getAllMusicians() {
return getMusicians().flatMap(artist -> Stream.concat(Stream.of(artist), artist.getMembers()));
}
}
}
}
|
stream流 reduce求和
1
2
3
4
5
|
BigDecimal lastEleSum = demoList.stream()
.filter(Objects::nonNull)
.map(s -> s.getLastEle())
.filter(Objects::nonNull)
.reduce(BigDecimal.ZERO, BigDecimal::add);
|
stream流 reducing使用
1
2
3
4
|
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.stream().collect(Collectors.reducing((s1, s2) -> s1 + s2)).orElse(0); // 求和结果:15
numbers.stream().collect(Collectors.reducing(Integer.MIN_VALUE, (a, b) -> a > b ? a : b)); // 最大值:5
numbers.stream().collect(Collectors.reducing(Integer.MAX_VALUE, n -> n, (a, b) -> a < b ? a : b)); // 最小值:1
|
list转map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
class list转map {
public static final Stream<User> filterStream = Optional.ofNullable(users).orElse(Collections.emptyList())
.stream()
.filter(Objects::nonNull)
.filter(s -> s.getGender() != null)
.filter(s -> s.getAge() != null)
.filter(s -> s.getScore() != null);
public static void main(String[] args) {
// 3参数
Map<Integer, User> map = filterStream.collect(toMap(User::getGender, Function.identity(), (s1, s2) -> s1));
// 4参数
TreeMap<Integer, User> treeMap = filterStream.collect(toMap(User::getGender,
Function.identity(),
BinaryOperator.maxBy(comparing(User::getScore)),
TreeMap::new));
// ⭐️上面去掉的重复元素,单独收集起来
// 迭代用户都不同的Map的value
HashMap<Integer, List<User>> other = new HashMap<>();
treeMap.values().forEach(s -> {
// 获取重复的那部分的map集合
Map<Integer, List<User>> listMap = filterStream
.filter(userAll -> Objects.equals(userAll.getGender(), s.getGender()) // 性别相同
&& Objects.equals(userAll.getScore(), s.getScore()) // 得分相同
&& (userAll.getEndTime().getTime() - userAll.getStartTime().getTime()) == (s.getEndTime().getTime() - s.getStartTime().getTime())) // 时间相同
.collect(toMap(
User::getGender,
user -> new ArrayList<>(Collections.singletonList(user)), // 映射成List
(list1, list2) -> { // 重复的合并
list2.addAll(list1);
return list2;
}));
other.putAll(listMap);
});
}
}
|
Stream流map原理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
/**
* 只用 reduce 和 Lambda 表达式写出实现 Stream 上的 map 操作的代码,如果不想返回 Stream,可以返回一个 List。
*/
class Stream流map原理 {
public static <I, O> List<O> map(Stream<I> stream, Function<I, O> mapper) {
return stream.reduce(new ArrayList<O>(), (acc, x) -> {
// 我们正在将数据从 acc 复制到新的列表实例。这是非常低效的,
// 但是 Stream.reduce 方法的合约要求累加器函数不改变其参数。
// Stream.collect方法可用于实现更有效的可变还原,
// 但是这个练习要求使用reduce方法。
List<O> newAcc = new ArrayList<>(acc);
newAcc.add(mapper.apply(x));
return newAcc;
}, (List<O> left, List<O> right) -> {
// 我们正在将左复制到新列表以避免更改它。
List<O> newLeft = new ArrayList<>(left);
newLeft.addAll(right);
return newLeft;
});
}
}
|
Stream流filter原理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
/**
* 只用 reduce 和 Lambda 表达式写出实现 Stream 上的 filter 操作的代码,如果不想返回 Stream,可以返回一个 List。
*/
class Stream流filter原理 {
public static <I> List<I> filter(Stream<I> stream, Predicate<I> predicate) {
List<I> initial = new ArrayList<>();
return stream.reduce(initial,
(List<I> acc, I x) -> {
if (predicate.test(x)) {
// We are copying data from acc to new list instance. It is very inefficient,
// but contract of Stream.reduce method requires that accumulator function does
// not mutate its arguments.
// Stream.collect method could be used to implement more efficient mutable reduction,
// but this exercise asks to use reduce method explicitly.
List<I> newAcc = new ArrayList<>(acc);
newAcc.add(x);
return newAcc;
} else {
return acc;
}
},
Stream流filter原理::combineLists);
}
private
static <I> List<I> combineLists(List<I> left, List<I> right) {
// We are copying left to new list to avoid mutating it.
List<I> newLeft = new ArrayList<>(left);
newLeft.addAll(right);
return newLeft;
}
}
|
Supplier
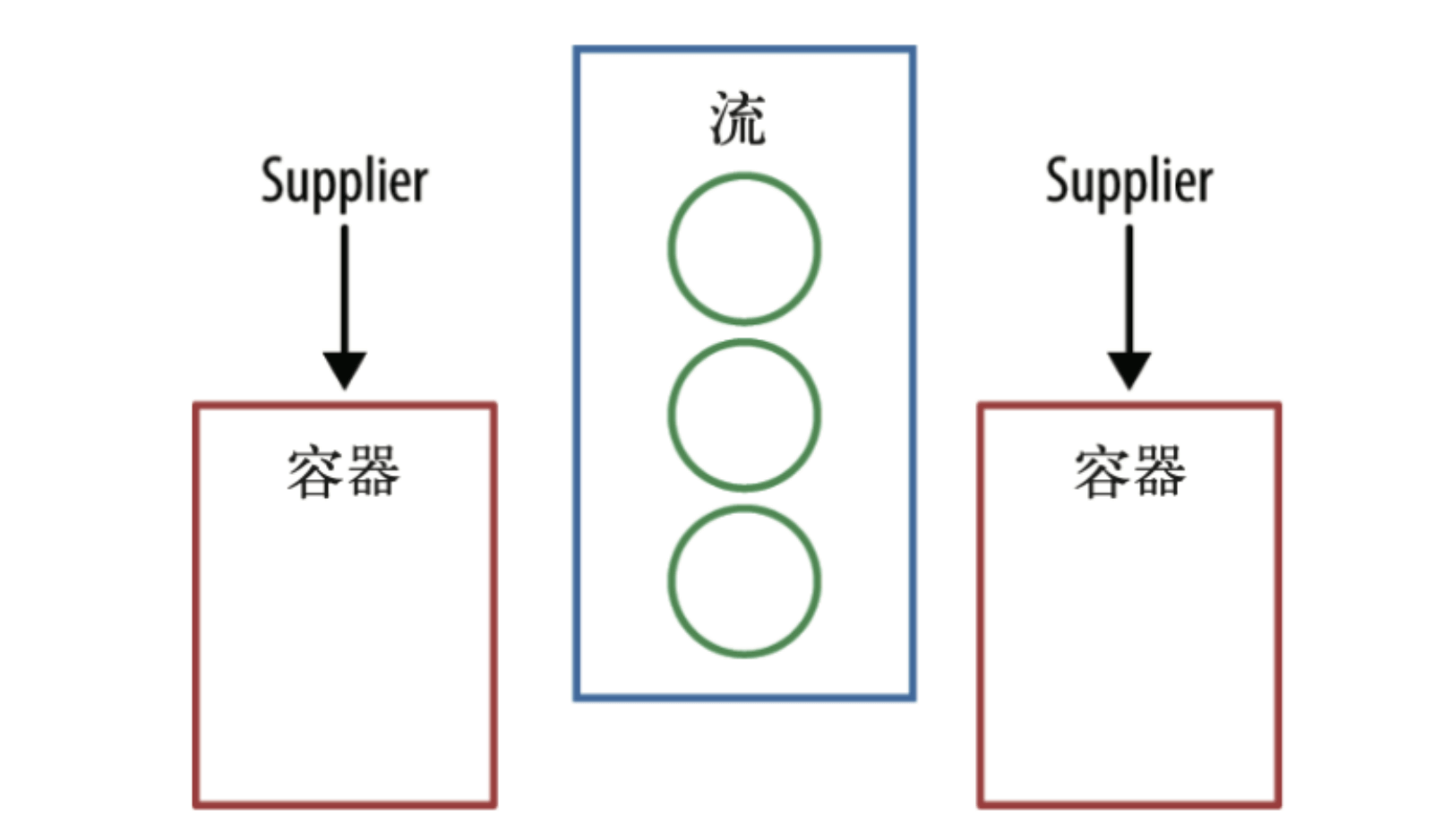
实现原理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
|
/**
* <p> 重构和定制收集器
* <p> 以下代码在工作中没有必要这样做, JDK 已经提供了一个完美的收集器 joining。
* <p> 这里只是为了展示如何定制收集器,以及如 何使用 Java 8 提供的新功能来重构遗留代码。
* <p>
* <p> 读者也许会认为 StringCombiner 看起来非常有用,别担心——你没必要亲自去编写,
* <p> Java 8 有一个 java.util.StringJoiner 类,它的作用和 StringCombiner 一样,有类似的 API。
*/
public class StringCombiner {
/**
* 使用 for 循环和 StringBuilder 格式化艺术家姓名
*/
@Test
void for_StringBuilder() {
List<Artist> artists = SampleData.getThreeArtists();
StringBuilder builder = new StringBuilder("[");
for (Artist artist : artists) {
if (builder.length() > 1) builder.append(", ");
String name = artist.getName();
builder.append(name);
}
builder.append("]");
String result = builder.toString();
}
/**
* 使用 forEach 和 StringBuilder 格式化艺术家姓名
*/
@Test
void forEach_StringBuilder() {
List<Artist> artists = SampleData.getThreeArtists();
StringBuilder builder = new StringBuilder("[");
artists.stream()
.map(Artist::getName)
.forEach(name -> {
if (builder.length() > 1)
builder.append(", ");
builder.append(name);
});
builder.append("]");
String result = builder.toString();
}
/**
* 使用 reduce 和 StringBuilder 格式化艺术家姓名
*/
@Test
void reduce_StringBuilder() {
List<Artist> artists = SampleData.getThreeArtists();
StringBuilder reduced =
artists.stream()
.map(Artist::getName)
.reduce(new StringBuilder(), (builder, name) -> {
if (builder.length() > 0)
builder.append(", ");
builder.append(name);
return builder;
}, (left, right) -> left.append(right));
reduced.insert(0, "[");
reduced.append("]");
String result = reduced.toString();
}
/**
* 使用 reduce 和 StringCombiner 类格式化艺术家姓名
*/
@Test
void name() {
StringCombiner combined = artists.stream()
.map(Artist::getName)
.reduce(new StringCombiner(", ", "[", "]"),
StringCombiner::add,
StringCombiner::merge);
String result = combined.toString();
}
@Test
void name() {
// add 方法返回连接新元素后的结果
public StringCombiner add (String element){
if (areAtStart()) {
builder.append(prefix);
} else {
builder.append(delim);
}
builder.append(element);
return this;
}
// merge 方法连接两个 StringCombiner 对象
public StringCombiner merge (StringCombiner other){
builder.append(other.builder);
return this;
}
// 例 5-20: 使用 reduce 操作,将工作代理给 StringCombiner 对象
String result = artists.stream()
.map(Artist::getName)
.reduce(new StringCombiner(", ", "[", "]"),
StringCombiner::add,
StringCombiner::merge)
.toString();
// 使用定制的收集器 StringCollector 收集字符串
String result = artists.stream()
.map(Artist::getName)
.collect(new StringCollector(", ", "[", "]"));
// 定义字符串收集器
}
public class StringCollector implements Collector<String, StringCombiner, String> {
// 一个收集器由四部分组成。首先是一个 Supplier,这是一个工厂方法,用来创建容器,
// 在 这个例子中,就是 StringCombiner。
// 和 reduce 操作中的第一个参数类似,它是后续操作的 初值。
// Supplier 是创建容器的工厂
public Supplier<StringCombiner> supplier() {
return () -> new StringCombiner(delim, prefix, suffix);
}
// accumulator 是一个函数,它将当前元素叠加到收集器
public BiConsumer<StringCombiner, String> accumulator() {
return StringCombiner::add;
}
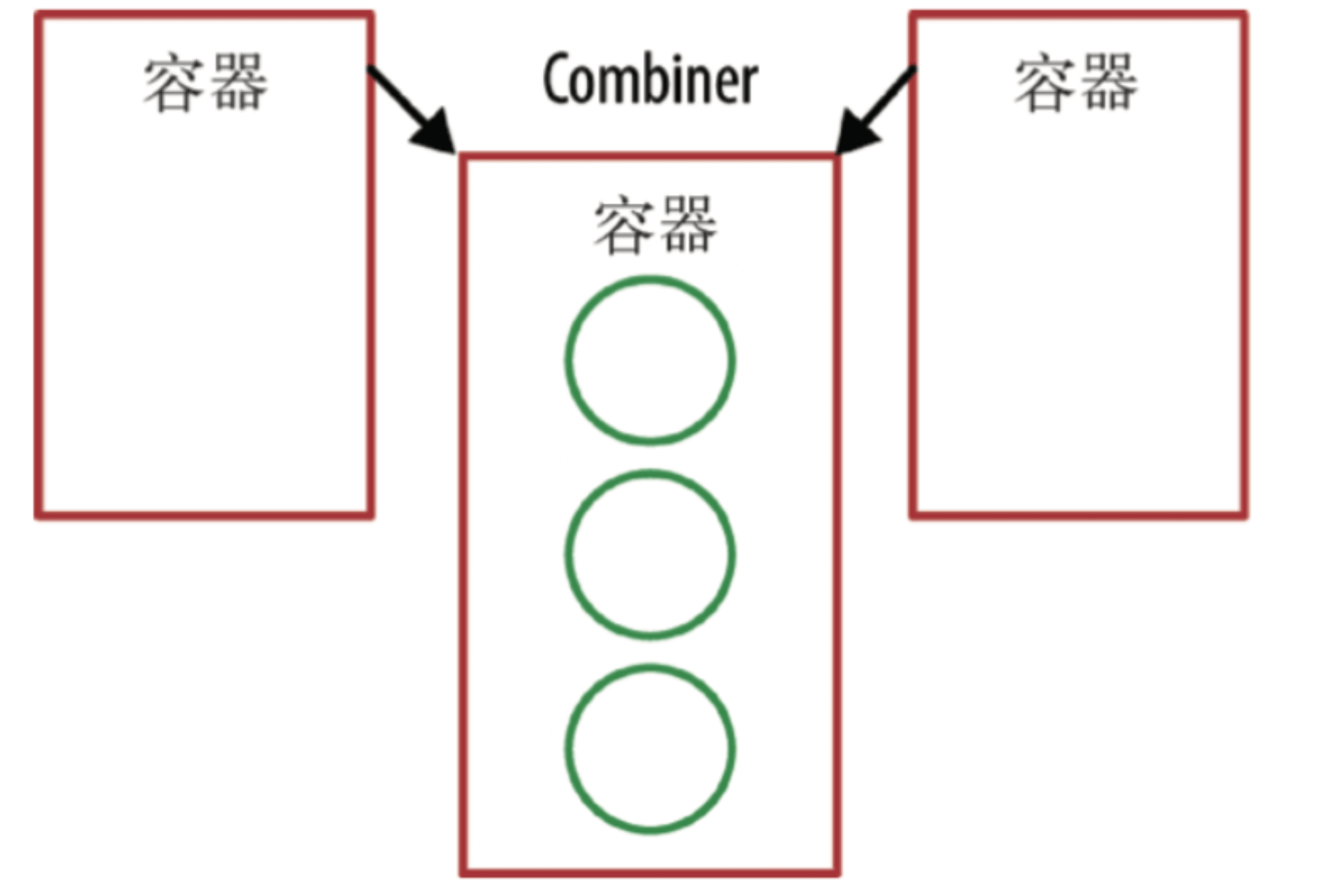
// combiner 合并两个容器
public BinaryOperator<StringCombiner> combiner() {
return StringCombiner::merge;
}
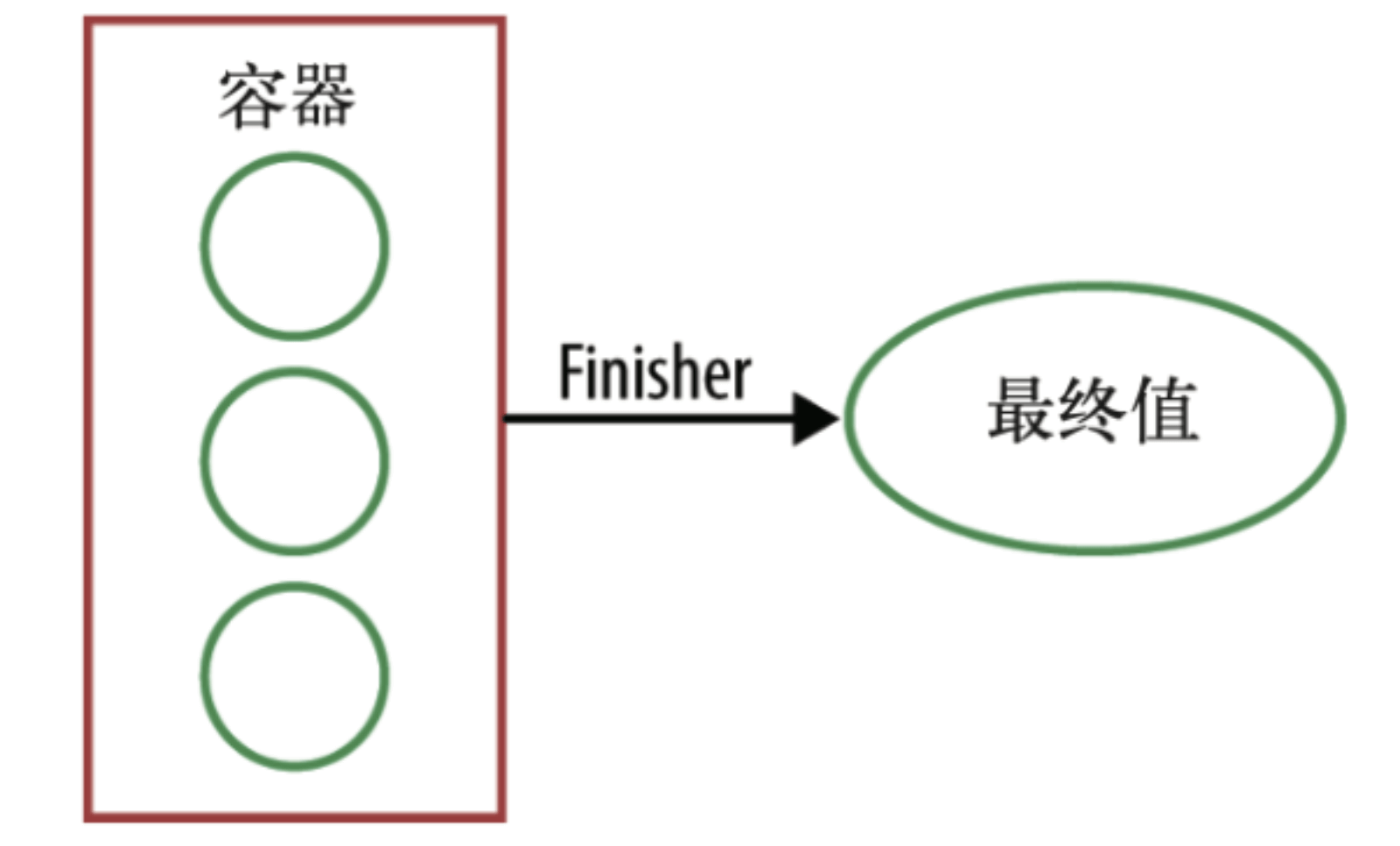
// finisher 方法返回收集操作的最终结果
public Function<StringCombiner, String> finisher() {
return StringCombiner::toString;
}
}
}
|
Accumulator

Combiner
Finisher
Lambda(行为参数化)
类型推断、重载解析
总而言之,Lambda 表达式作为参数时,其类型由它的目标类型推导得出,推导过程遵循 如下规则:
- 如果只有一个可能的目标类型,由相应函数接口里的参数类型推导得出;
- 如果有多个可能的目标类型,由最具体的类型推导得出;
- 如果有多个可能的目标类型且最具体的类型不明确,则需人为指定类型。
默认方法
三定律
如果对默认方法的工作原理,特别是在多重继承下的行为还没有把握,如下三条简单的定 律可以帮助大家。
- 类胜于接口。如果在继承链中有方法体或抽象的方法声明,那么就可以忽略接口中定义 的方法。
- 子类胜于父类。如果一个接口继承了另一个接口,且两个接口都定义了一个默认方法, 那么子类中定义的方法胜出。
- 没有规则三。如果上面两条规则不适用,子类要么需要实现该方法,要么将该方法声明为抽象方法。
其中第一条规则是为了让代码向后兼容。让类中重写方法的优先级高于默认方法能简化很多继承问题。
子类胜于父类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// Parent 接口,其中的 welcome 是一个默认方法
public interface Parent {
public void message(String body);
public default void welcome() {
message("Parent: Hi!");
}
public String getLastMessage();
}
// 继承了 Parent 接口的 Child 接口
public interface Child extends Parent {
@Override
public default void welcome() {
message("Child: Hi!");
}
}
// 调用 Child 接口的客户代码
@Test
public void childOverrideDefaultTest() {
Child child = new ChildImpl();
child.welcome();
assertEquals("Child: Hi!" , child.getLastMessage());
}
|
类胜于接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// 重写 welcome 默认实现的父类
public class OverridingParent extends ParentImpl {
@Override
public void welcome() {
message("Class Parent: Hi!");
}
}
// 调用的是类中的具体方法,而不是默认方法
@Test
public void concreteBeatsDefault() {
Parent parent = new OverridingParent();
parent.welcome();
assertEquals("Class Parent: Hi!" , parent.getLastMessage());
}
public class OverridingChild extends OverridingParent implements Child {
}
// 类中重写的方法优先级高于接口中定义的默认方法
@Test
public void concreteBeatsCloserDefault() {
Child child = new OverridingChild();
child.welcome();
assertEquals("Class Parent: Hi!" , child.getLastMessage());
}
|
多重继承
当一个类实现多个接口时,多个接口中存在同名的默认方法。 实现类必须重写这个方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public interface Jukebox {
public default String rock() {
return "... all over the world!";
}
}
public interface Carriage {
public default String rock() {
return "... from side to side";
}
}
public class MusicalCarriage implements Carriage, Jukebox {
}
// 编译器会报错:class Musical Carriage inherits unrelated defaults for rock() from types Carriage and Jukebox。
public class MusicalCarriage implements Carriage, Jukebox {
@Override
public String rock() {
return Carriage.super.rock();
}
}
|
元素顺序forEachOrdered
一些操作在有序的流上开销更大,调用 unordered 方法消除这种顺序就能解决该问题。大 多数操作都是在有序流上效率更高,比如 filter、map 和 reduce 等。
这会带来一些意想不到的结果,比如使用并行流时,forEach 方法不能保证元素是 按顺序处理的(第 6 章会详细讨论这些内容) 。如果需要保证按顺序处理,应该使用 forEachOrdered 方法,它是你的朋友。
下游收集器
收集器是生成最终结果的一剂配方,下游收集器则是生成部分结果的配方,主收集器中会用到下游收集器。
对收集器的归一化处理
1
2
3
4
5
6
7
8
9
10
11
|
// reducing 是一种定制收集器的简便方式
String result=artists.stream()
.map(Artist::getName)
.collect(Collectors.reducing(
new StringCombiner(", ","[","]"),
name->new StringCombiner(", ","[","]").add(name),
StringCombiner::merge))
.toString();
// 这和我在例 5-20 中讲到的基于 reduce 操作的实现很像,这点从方法名中就能看出。
// 区别在于 Collectors.reducing 的第二个参数,我们为流中每个元素创建了唯一的 StringCombiner。
// 如果你被这种写法吓到了,或是感到恶心,你不是一个人!这种方式非 常低效,这也是我要定制收集器的原因之一。
|
computeIfAbsent 缓存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// 使用显式判断空值的方式缓存
public Artist getArtist(String name) {
Artist artist = artistCache.get(name);
if (artist == null) {
artist = readArtistFromDB(name);
artistCache.put(name, artist);
}
return artist;
}
// 使用 computeIfAbsent 缓存
public Artist getArtist(String name) {
return artistCache.computeIfAbsent(name, this::readArtistFromDB);
}
|
使用内部迭代遍历 Map 里的值
1
2
3
4
|
Map<Artist, Integer> countOfAlbums=new HashMap<>();
albumsByArtist.forEach((artist,albums)->{
countOfAlbums.put(artist,albums.size());
});
|
练习
收集器
a.找出名字最长的艺术家,分别使用收集器和第 3 章介绍过的 reduce 高阶函数实现。
然后对比二者的异同:哪一种方式写起来更简单,哪一种方式读起来更简单?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// 以下面的参数为例,该方法的正确返回值为 "Stuart Sutcliffe":
Stream<String> names=Stream.of("John Lennon","Paul McCartney",
"George Harrison","Ringo Starr","Pete Best","Stuart Sutcliffe");
public class LongestName {
private static Comparator<Artist> byNameLength = comparing(artist -> artist.getName().length());
public static Artist byReduce(List<Artist> artists) {
return artists.stream()
.reduce((acc, artist) -> {
return (byNameLength.compare(acc, artist) >= 0) ? acc : artist;
})
.orElseThrow(RuntimeException::new);
}
public static Artist byCollecting(List<Artist> artists) {
return artists.stream()
.collect(Collectors.maxBy(byNameLength))
.orElseThrow(RuntimeException::new);
}
}
|
c.用一个定制的收集器实现 Collectors.groupingBy 方法,不需要提供一个下游收集器,
这是一个进阶练习,不妨最后再尝试这道习题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
// 只需实现一个最简单的即可。别看 JDK 的源码,这是作弊!提示:可从下面这行代码开始:
public class GroupingBy<T, K> implements Collector<T, Map<K, List<T>>, Map<K,
List<T>>>
public class GroupingBy<T, K> implements Collector<T, Map<K, List<T>>, Map<K, List<T>>> {
private final static Set<Characteristics> characteristics = new HashSet<>();
static {
characteristics.add(Characteristics.IDENTITY_FINISH);
}
private final Function<? super T, ? extends K> classifier;
public GroupingBy(Function<? super T, ? extends K> classifier) {
this.classifier = classifier;
}
@Override
public Supplier<Map<K, List<T>>> supplier() {
return HashMap::new;
}
@Override
public BiConsumer<Map<K, List<T>>, T> accumulator() {
return (map, element) -> {
K key = classifier.apply(element);
List<T> elements = map.computeIfAbsent(key, k -> new ArrayList<>());
elements.add(element);
};
}
@Override
public BinaryOperator<Map<K, List<T>>> combiner() {
return (left, right) -> {
right.forEach((key, value) -> {
left.merge(key, value, (leftValue, rightValue) -> {
leftValue.addAll(rightValue);
return leftValue;
});
});
return left;
};
}
@Override
public Function<Map<K, List<T>>, Map<K, List<T>>> finisher() {
return map -> map;
}
@Override
public Set<Characteristics> characteristics() {
return characteristics;
}
}
|
改进Map
使用 Map 的 computeIfAbsent 方法高效计算斐波那契数列。这里的“高效”是指避免将那 些较小的序列重复计算多次。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public class Fibonacci {
private final Map<Integer, Long> cache;
public Fibonacci() {
cache = new HashMap<>();
cache.put(0, 0L);
cache.put(1, 1L);
}
public long fibonacci(int x) {
return cache.computeIfAbsent(x, n -> fibonacci(n - 1) + fibonacci(n - 2));
}
}
|
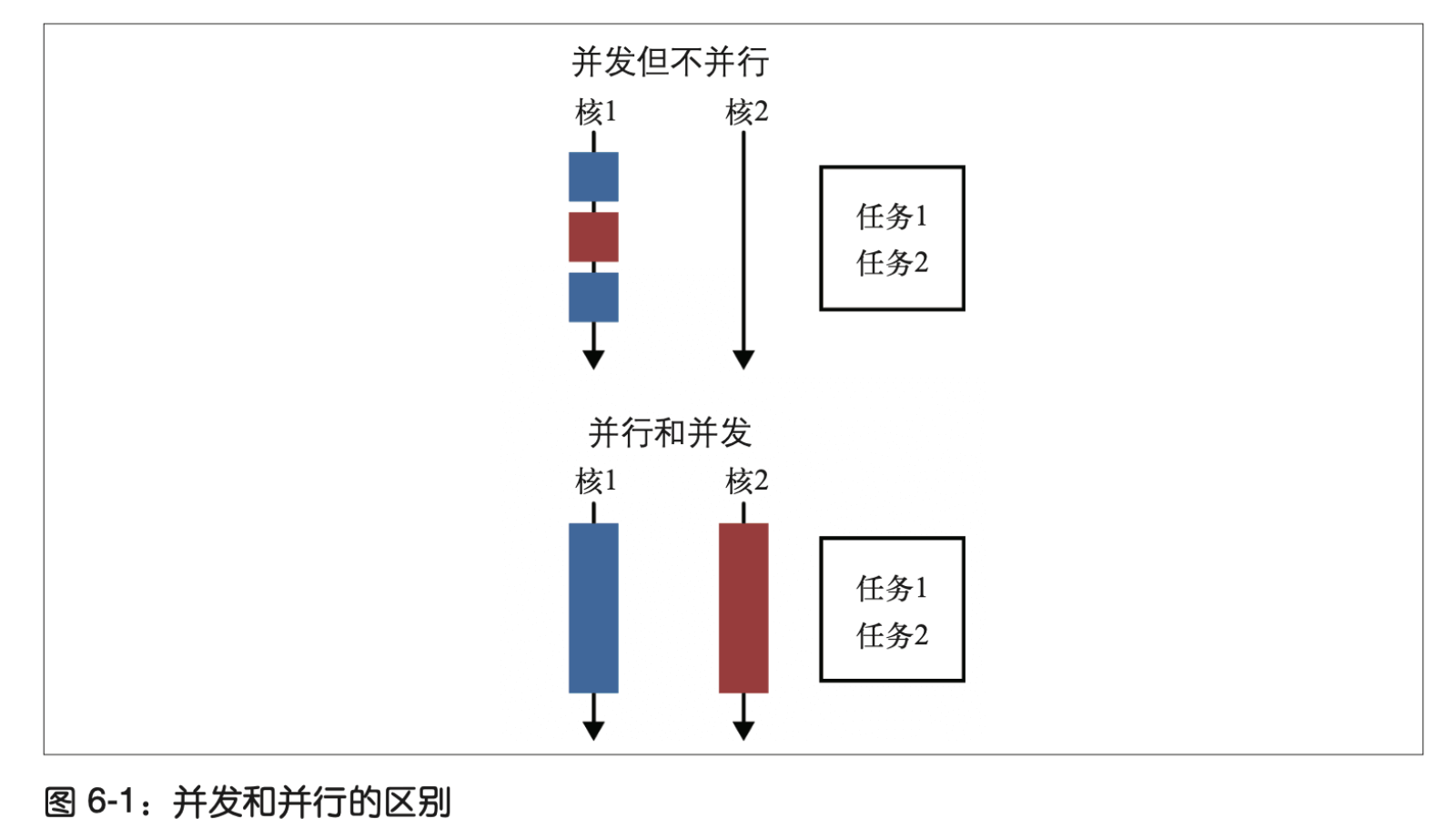
数据并行化
并行和并发
并发是两个任务共享时间段,并行则是两个任务在同一时间发生,比如运行在多核 CPU 上。 如果一个程序要运行两个任务,并且只有一个 CPU 给它们分配了不同的时间片,那 么这就是并发,而不是并行。
限制
之前调用 reduce 方法,初始值可以为任意值,为了让其在并行化时能工作正常,初值必须 为组合函数的恒等值。
reduce 操作的另一个限制是组合操作必须符合结合律。
要避免的是持有锁。流框架会在需要时,自己处理同步操作,因此程序员没有必要为自己 的数据结构加锁。如果你执意为流中要使用的数据结构加锁,比如操作的原始集合,那么 有可能是自找麻烦。
在前面我还解释过,使用 parallel 方法能轻易将流转换为并行流。如果读者在阅读本书的 同时,还查看了相应的 API,那么可能会发现还有一个叫 sequential 的方法。在要对流求 值时,不能同时处于两种模式,要么是并行的,要么是串行的。如果同时调用了 parallel 和 sequential 方法,最后调用的那个方法起效。
性能
数据并行化是把工作拆分,同时在多核CPU上执行的方式。
如果使用流编写代码,可通过调用parallel或者parallelStream方法实现数据并行化操作。
影响性能的五要素是:数据大小、源数据结构、值是否装箱、可用的CPU核数量,以及处理每个元素所花的时间。
- 数据大小
- 源数据结构
- 装箱
- 核的数量
- 单元处理开销
我们可以根据性能的好坏,将核心类库提供的通用数据结构分成以下 3 组。
- 性能好 ArrayList、数组或 IntStream.range,这些数据结构支持随机读取,也就是说它们能轻 而易举地被任意分解。
- 性能一般 HashSet、TreeSet,这些数据结构不易公平地被分解,但是大多数时候分解是可能的。
- 性能差 有些数据结构难于分解,比如,可能要花 O(N) 的时间复杂度来分解问题。其中包括 LinkedList,对半分解太难了。还有 Streams.iterate 和 BufferedReader.lines,它们 长度未知,因此很难预测该在哪里分解。
如果能避开有状态,选用无状态操作,就能获得更好的并行性能。无状态操作包括 map、 filter 和 flatMap,有状态操作包括 sorted、distinct 和 limit。
并行化数组操作
数组上的并行化操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
parallelPrefix 任意给定一个函数,计算数组的和
parallelSetAll 使用 Lambda 表达式更新数组元素
parallelSort 并行化对数组元素排序
// 使用并行化数组操作初始化数组
public static double[]parallelInitialize(int size){
double[]values=new double[size];
Arrays.parallelSetAll(values,i->i);
return values;
}
// 计算简单滑动平均数
public static double[]simpleMovingAverage(double[]values,int n){
double[]sums=Arrays.copyOf(values,values.length);
Arrays.parallelPrefix(sums,Double::sum);
intstart=n-1;
return IntStream
.range(start,sums.length)
.mapToDouble(i->{
double prefix=i==start?0:sums[i-n];
return(sums[i]-prefix)/n;
})
.toArray();
}
|
练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// 顺序求列表中数字的平方和
public static int sequentialSumOfSquares(IntStream range){
return range.map(x->x*x)
.sum();
}
// 将其改为并行处理。
public static int sumOfSquares(IntStream range){
return range.parallel()
.map(x->x*x)
.sum();
}
// 把列表中的数字相乘,然后再将所得结果乘以 5,该实现有一个缺陷
public static int multiplyThrough(List<Integer> linkedListOfNumbers){
return linkedListOfNumbers.stream()
.reduce(5,(acc,x)->x*acc);
}
// 使用流并行化执行该段代码,并修复缺陷。
public static int multiplyThrough(List<Integer> numbers){
return 5*numbers.parallelStream()
.reduce(1,(acc,x)->x*acc);
}
// 求列表元素的平方和,该实现方式性能不高
public int slowSumOfSquares(){
return linkedListOfNumbers.parallelStream()
.map(x->x*x)
.reduce(0,(acc,x)->acc+x);
}
//
|
测试、调试、重构
重构候选项
进进出出、摇摇晃晃
1
2
3
4
5
6
7
8
9
|
// logger 对象使用 isDebugEnabled 属性避免不必要的性能开销
Logger logger=new Logger();
if(logger.isDebugEnabled()){
logger.debug("Look at this: "+expensiveOperation());
}
// 使用 Lambda 表达式简化记录日志代码
Logger logger=new Logger();
logger.debug(()->"Look at this: "+expensiveOperation());
|
孤独的覆盖
1
2
3
4
5
6
7
8
9
10
11
12
|
// 在数据库中查找艺术家
ThreadLocal<Album> thisAlbum = new ThreadLocal<Album> (){
@Override
protected Album initialValue(){
return database.lookupCurrentAlbum();
}
};
// 使用工厂方法
// 在Java 8中,可以为工厂方法withInitial传入一个Supplier对象的实例来创建对象,如
ThreadLocal<Album> thisAlbum =
ThreadLocal.withInitial(()->database.lookupCurrentAlbum());
|
同样的东西写两遍
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
// Order 类的命令式实现
public long countRunningTime(){
long count=0;
for(Album album:albums){
for(Track track:album.getTrackList()){
count+=track.getLength();
}
}
return count;
}
public long countMusicians(){
long count=0;
for(Album album:albums){
count+=album.getMusicianList().size();
}
return count;
}
public long countTracks(){
long count=0;
for(Album album:albums){
count+=album.getTrackList().size();
}
return count;
}
//使用流重构命令式的 Order 类
public long countRunningTime(){
return albums.stream()
.mapToLong(album->album.getTracks()
.mapToLong(track->track.getLength())
.sum())
.sum();
}
public long countMusicians(){
return albums.stream()
.mapToLong(album->album.getMusicians().count())
.sum();
}
public long countTracks(){
return albums.stream()
.mapToLong(album->album.getTracks().count())
.sum();
}
// 使用领域方法重构 Order 类
public long countFeature(ToLongFunction<Album> function){
return albums.stream()
.mapToLong(function)
.sum();
}
public long countTracks(){
return countFeature(album->album.getTracks().count());
}
public long countRunningTime(){
return countFeature(album->album.getTracks()
.mapToLong(track->track.getLength())
.sum());
}
public long countMusicians(){
return countFeature(album->album.getMusicians().count());
}
|
Lambda表达式的单元测试
第一种是将 Lambda 表达式放入一个方法测试,这种方式要测那 个方法,而不是 Lambda 表达式本身。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
// 将字符串转换为大写形式
public static List<String> allToUpperCase(List<String> words){
return words.stream()
.map(string->string.toUpperCase())
.collect(Collectors.<String>toList());
}
// 测试大写转换
@Test
public void multipleWordsToUppercase(){
List<String> input=Arrays.asList("a","b","hello");
List<String> result=Testing.allToUpperCase(input);
assertEquals(asList("A","B","HELLO"),result);
}
// 将列表中元素的第一个字母转换成大写
public static List<String> elementFirstToUpperCaseLambdas(List<String> words){
return words.stream()
.map(value->{
char firstChar=Character.toUpperCase(value.charAt(0));
return firstChar+value.substring(1);
})
.collect(Collectors.<String>toList());
}
// 测试字符串包含两个字符的情况,第一个字母被转换为大写
@Test
public void twoLetterStringConvertedToUppercaseLambdas(){
List<String> input=Arrays.asList("ab");
List<String> result=Testing.elementFirstToUpperCaseLambdas(input);
assertEquals(asList("Ab"),result);
}
// 应当用方法引用重构:
// 将 Lambda 表达式重构为一个方法,然后在主程序中使用,主程序负责转换字符串。
// 将首字母转换为大写,应用到所有列表元素
public static List<String> elementFirstToUppercase(List<String> words){
return words.stream()
.map(Testing::firstToUppercase)
.collect(Collectors.<String>toList());
}
public static String firstToUppercase(String value){
char firstChar=Character.toUpperCase(value.charAt(0));
return firstChar+value.substring(1);
}
// 把处理字符串的的逻辑抽取成一个方法后,就可以测试该方法,把所有的边界情况都覆盖 到。
@Test
public void twoLetterStringConvertedToUppercase(){
String input="ab";
String result=Testing.firstToUppercase(input);
assertEquals("Ab",result);
}
|
在测试替身时使用Lambda表达式
测试代码时,使用 Lambda 表达式的最简单方式是实现轻量级的测试存根。
1
2
3
4
5
6
7
8
9
|
// 使用 Lambda 表达式编写测试替身,传给 countFeature 方法
@Test
public void canCountFeatures(){
OrderDomain order=new OrderDomain(asList(newAlbum("Exile on Main St."),
newAlbum("Beggars Banquet"),
newAlbum("Aftermath"),
newAlbum("Let it Bleed")));
assertEquals(8,order.countFeature(album->2));
}
|
结合 Mockito 框架使用 Lambda 表达式
1
2
3
4
|
List<String> list=mock(List.class);
when(list.size())
.thenAnswer(inv->otherList.size());
assertEquals(3,list.size());
|
设计和架构的原则
软件开发最重要的设计工具不是什么技术,而是一颗在设计原则方面训练有素的头脑。
Lambda表达式改变了设计模式
命令者模式
